
I need to program a very simple Android app, whats the status of Fivetouch
Antonio... FiveTouch posts are gone?
Antonio... FiveTouch posts are gone?
Antonio, there is no Fivetouch posts in the forum 
I need to program a very simple Android app, whats the status of Fivetouch
I need to program a very simple Android app, whats the status of Fivetouch
http://www.xdata.cl - Desarrollo Inteligente
----------
Asus TUF F15, 32GB Ram, 2 * 1 TB NVME M.2, GTX 1650
-
Antonio Linares

- Site Admin
- Posts: 42393
- Joined: Thu Oct 06, 2005 5:47 pm
- Location: Spain
- Has thanked: 9 times
- Been thanked: 41 times
- Contact:
Re: Antonio... FiveTouch posts are gone?
Estimado Adolfo,
FiveTouch have mucho que dejó de actualizarse pues entendimos que una web app era una solución más idónea usando mod_harbour ó UT de Charly (más sencillo)
En la actualización de los foros, esos mensaje se han perdido. No sabemos por qué. De todas formas hay backup de todo y en una DBF:
https://huggingface.co/datasets/fivetec ... /tree/main
FiveTouch have mucho que dejó de actualizarse pues entendimos que una web app era una solución más idónea usando mod_harbour ó UT de Charly (más sencillo)
En la actualización de los foros, esos mensaje se han perdido. No sabemos por qué. De todas formas hay backup de todo y en una DBF:
https://huggingface.co/datasets/fivetec ... /tree/main
-
Otto

- Posts: 6396
- Joined: Fri Oct 07, 2005 7:07 pm
- Has thanked: 8 times
- Been thanked: 1 time
- Contact:
Re: Antonio... FiveTouch posts are gone?
Dear Antonio,
I have split the DBF memo fields into TXT files, all in one directory. There are 276,748 TXT files. When I now perform a search with
it takes about 50 seconds.
I think if you were to split the TXT files into groups and then start multiple searches simultaneously, this time could be significantly reduced.
In any case, it is a good real database to test my low-level functions.
Best regards,
Otto
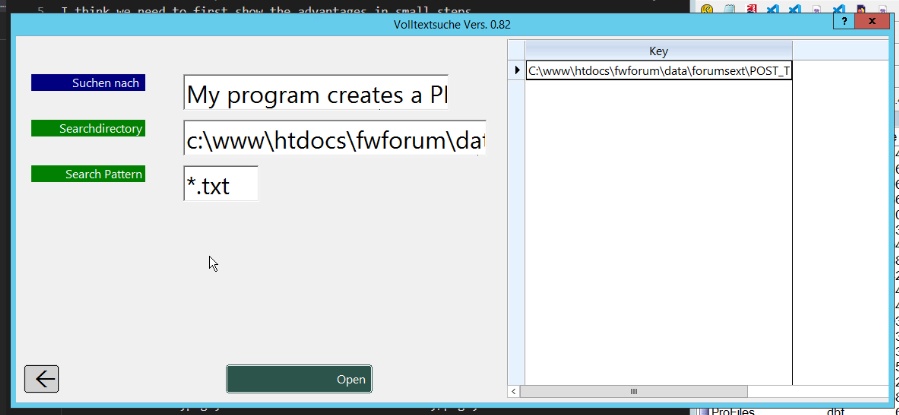
I have split the DBF memo fields into TXT files, all in one directory. There are 276,748 TXT files. When I now perform a search with
Code: Select all | Expand
Get-ChildItem -Path c:\www\htdocs\fwforum\data\forumsext\POST_TEXT_memo -Recurse -Filter *.txt | Select-String -Pattern "My program creates a PDF" | ForEach-Object { $_.Path } | Out-File -FilePath "search_results.txt" -Encoding ASCIII think if you were to split the TXT files into groups and then start multiple searches simultaneously, this time could be significantly reduced.
In any case, it is a good real database to test my low-level functions.
Best regards,
Otto
********************************************************************
mod harbour - Vamos a la conquista de la Web
modharbour.org
https://www.facebook.com/groups/modharbour.club
********************************************************************
mod harbour - Vamos a la conquista de la Web
modharbour.org
https://www.facebook.com/groups/modharbour.club
********************************************************************
-
Antonio Linares
- Site Admin
- Posts: 42393
- Joined: Thu Oct 06, 2005 5:47 pm
- Location: Spain
- Has thanked: 9 times
- Been thanked: 41 times
- Contact:
Re: Antonio... FiveTouch posts are gone?
Dear Otto,
> I have split the DBF memo fields into TXT files, all in one directory. There are 276,748 TXT files. When I now perform a search with
Would you be so kind to share it ?
You may send it to me using https://wormhole.app/ or https://huggingface.co/
Thank you very much
> I have split the DBF memo fields into TXT files, all in one directory. There are 276,748 TXT files. When I now perform a search with
Would you be so kind to share it ?
You may send it to me using https://wormhole.app/ or https://huggingface.co/
Thank you very much

Re: Antonio... FiveTouch posts are gone?
hi Otto,
it is a old Problem when have so many Files in a Directory that it need a long Time to read all Files.
it also depends on File System :
FAT32 (Windows): The maximum number of files in a single directory is 65,534.
50 Sec. is a long Time !Otto wrote: Tue Jan 21, 2025 11:10 pm I have split the DBF memo fields into TXT files, all in one directory. There are 276,748 TXT files. When I now perform a search with
it takes about 50 seconds.
it is a old Problem when have so many Files in a Directory that it need a long Time to read all Files.
it also depends on File System :
FAT32 (Windows): The maximum number of files in a single directory is 65,534.
greeting,
Jimmy
Jimmy
-
Otto
- Posts: 6396
- Joined: Fri Oct 07, 2005 7:07 pm
- Has thanked: 8 times
- Been thanked: 1 time
- Contact:
Re: Antonio... FiveTouch posts are gone?
Hello Jimmy,
yes, you're right. Even TC takes a very long time to build the view in a directory with so many files.
But I think it's a good exercise for me. I simply don’t want an SQL database at the moment.
Still, I wonder why searches in SQL can be so fast.
Yesterday, I experimented further and split the directory into 4 parts, now performing the search with ripgrep and 4 parallel calls.
Now it takes 12 seconds. In the evening, I’ll test again with 8 directories.
At the moment, I’m working on creating an index file. For my purpose in a DMS system, it works well, even if the first search takes longer.
But since I can then work with the original files, I see this approach as a good fit.
This first test with the index file didn’t work yet.
Best regards,
Otto
yes, you're right. Even TC takes a very long time to build the view in a directory with so many files.
But I think it's a good exercise for me. I simply don’t want an SQL database at the moment.
Still, I wonder why searches in SQL can be so fast.
Yesterday, I experimented further and split the directory into 4 parts, now performing the search with ripgrep and 4 parallel calls.
Now it takes 12 seconds. In the evening, I’ll test again with 8 directories.
At the moment, I’m working on creating an index file. For my purpose in a DMS system, it works well, even if the first search takes longer.
But since I can then work with the original files, I see this approach as a good fit.
This first test with the index file didn’t work yet.
Best regards,
Otto
********************************************************************
mod harbour - Vamos a la conquista de la Web
modharbour.org
https://www.facebook.com/groups/modharbour.club
********************************************************************
mod harbour - Vamos a la conquista de la Web
modharbour.org
https://www.facebook.com/groups/modharbour.club
********************************************************************
-
Otto
- Posts: 6396
- Joined: Fri Oct 07, 2005 7:07 pm
- Has thanked: 8 times
- Been thanked: 1 time
- Contact:
Re: Antonio... FiveTouch posts are gone?
Dear Antonio,
Which data should I upload?
Best regards,
Otto
Which data should I upload?
Best regards,
Otto
********************************************************************
mod harbour - Vamos a la conquista de la Web
modharbour.org
https://www.facebook.com/groups/modharbour.club
********************************************************************
mod harbour - Vamos a la conquista de la Web
modharbour.org
https://www.facebook.com/groups/modharbour.club
********************************************************************
-
Antonio Linares
- Site Admin
- Posts: 42393
- Joined: Thu Oct 06, 2005 5:47 pm
- Location: Spain
- Has thanked: 9 times
- Been thanked: 41 times
- Contact:
Re: Antonio... FiveTouch posts are gone?
Dear Otto,
never mind. We already found a bug we were looking for
never mind. We already found a bug we were looking for
-
Antonio Linares
- Site Admin
- Posts: 42393
- Joined: Thu Oct 06, 2005 5:47 pm
- Location: Spain
- Has thanked: 9 times
- Been thanked: 41 times
- Contact:
Re: Antonio... FiveTouch posts are gone?
Mensajes arregladosAdolfo wrote: Mon Jan 20, 2025 2:40 pm Antonio, there is no Fivetouch posts in the forum
I need to program a very simple Android app, whats the status of Fivetouch
https://forums.fivetechsupport.com/view ... hp?t=35529
-
Otto
- Posts: 6396
- Joined: Fri Oct 07, 2005 7:07 pm
- Has thanked: 8 times
- Been thanked: 1 time
- Contact:
Re: Antonio... FiveTouch posts are gone?
Experiment to Optimize Full-Text Search in Memo Files
I conducted an exciting experiment to optimize full-text search in memo files. Here's a brief summary:
Initial Situation:
Data: Memo fields from a DBF file (forums.dbf, 921 MB, 271,585 records) were exported into 271,585 individual TXT files.
Problem: Searching in a folder containing all TXT files took 50 seconds.
Optimizations:
File Distribution:
The files were distributed across 4 folders.
Using rg.exe (ripgrep) and parallel searching reduced the time to 12–14 seconds.
Index File:
A central index file was created, containing all texts from the memo files.
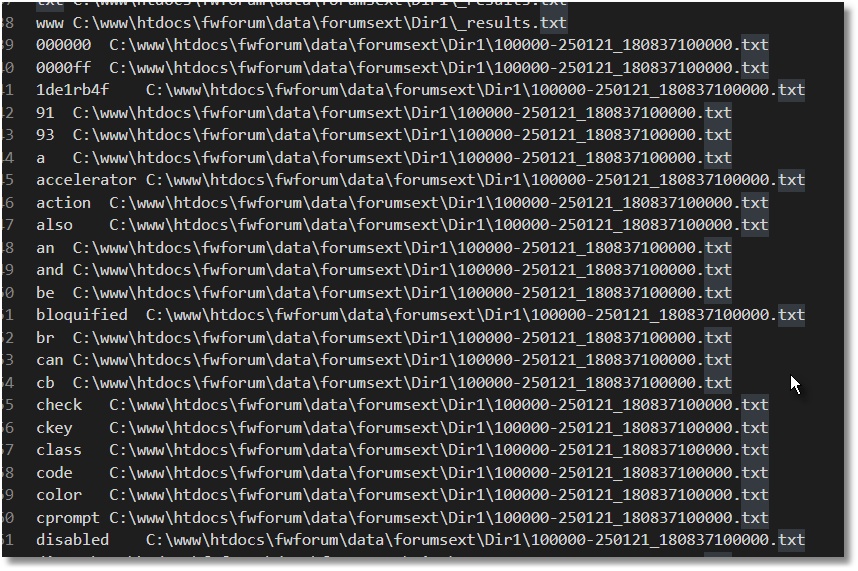
Direct Search with rg.exe:
The direct search with rg.exe in the index file is blazing fast, taking only 0.335 seconds.

Next Steps:
Temporary Index File:
A temporary index file will be created during changes, and the main index file will be updated incrementally.
Conclusion:
rg.exe is a game-changer: It provides SQL-like speed for full-text searches.
Simplicity and Transparency: The solution uses simple tools while maintaining full control over the data.
I'm excited to hear your thoughts and suggestions!
Best regards,
Otto
I conducted an exciting experiment to optimize full-text search in memo files. Here's a brief summary:
Initial Situation:
Data: Memo fields from a DBF file (forums.dbf, 921 MB, 271,585 records) were exported into 271,585 individual TXT files.
Problem: Searching in a folder containing all TXT files took 50 seconds.
Optimizations:
File Distribution:
The files were distributed across 4 folders.
Using rg.exe (ripgrep) and parallel searching reduced the time to 12–14 seconds.
Index File:
A central index file was created, containing all texts from the memo files.
Direct Search with rg.exe:
The direct search with rg.exe in the index file is blazing fast, taking only 0.335 seconds.
Next Steps:
Temporary Index File:
A temporary index file will be created during changes, and the main index file will be updated incrementally.
Conclusion:
rg.exe is a game-changer: It provides SQL-like speed for full-text searches.
Simplicity and Transparency: The solution uses simple tools while maintaining full control over the data.
I'm excited to hear your thoughts and suggestions!
Best regards,
Otto
********************************************************************
mod harbour - Vamos a la conquista de la Web
modharbour.org
https://www.facebook.com/groups/modharbour.club
********************************************************************
mod harbour - Vamos a la conquista de la Web
modharbour.org
https://www.facebook.com/groups/modharbour.club
********************************************************************
-
Otto
- Posts: 6396
- Joined: Fri Oct 07, 2005 7:07 pm
- Has thanked: 8 times
- Been thanked: 1 time
- Contact:
Re: Antonio... FiveTouch posts are gone?
********************************************************************
mod harbour - Vamos a la conquista de la Web
modharbour.org
https://www.facebook.com/groups/modharbour.club
********************************************************************
mod harbour - Vamos a la conquista de la Web
modharbour.org
https://www.facebook.com/groups/modharbour.club
********************************************************************
-
Otto
- Posts: 6396
- Joined: Fri Oct 07, 2005 7:07 pm
- Has thanked: 8 times
- Been thanked: 1 time
- Contact:
Re: Antonio... FiveTouch posts are gone?
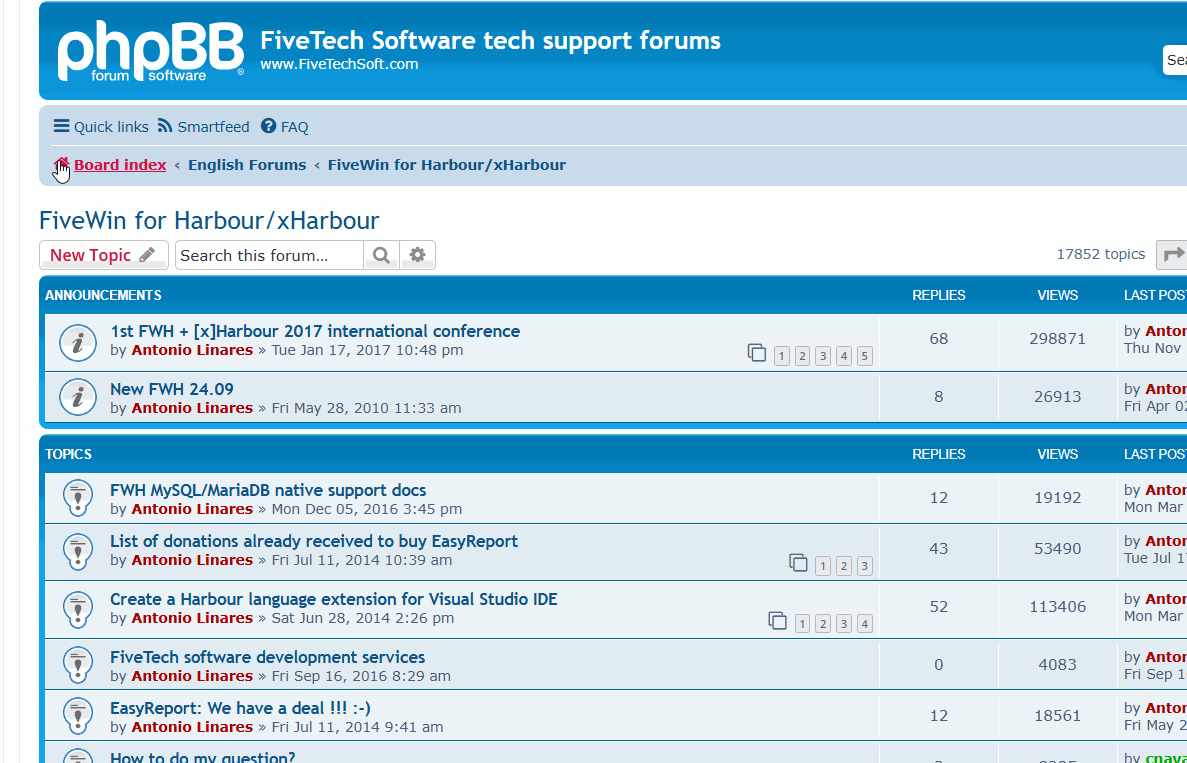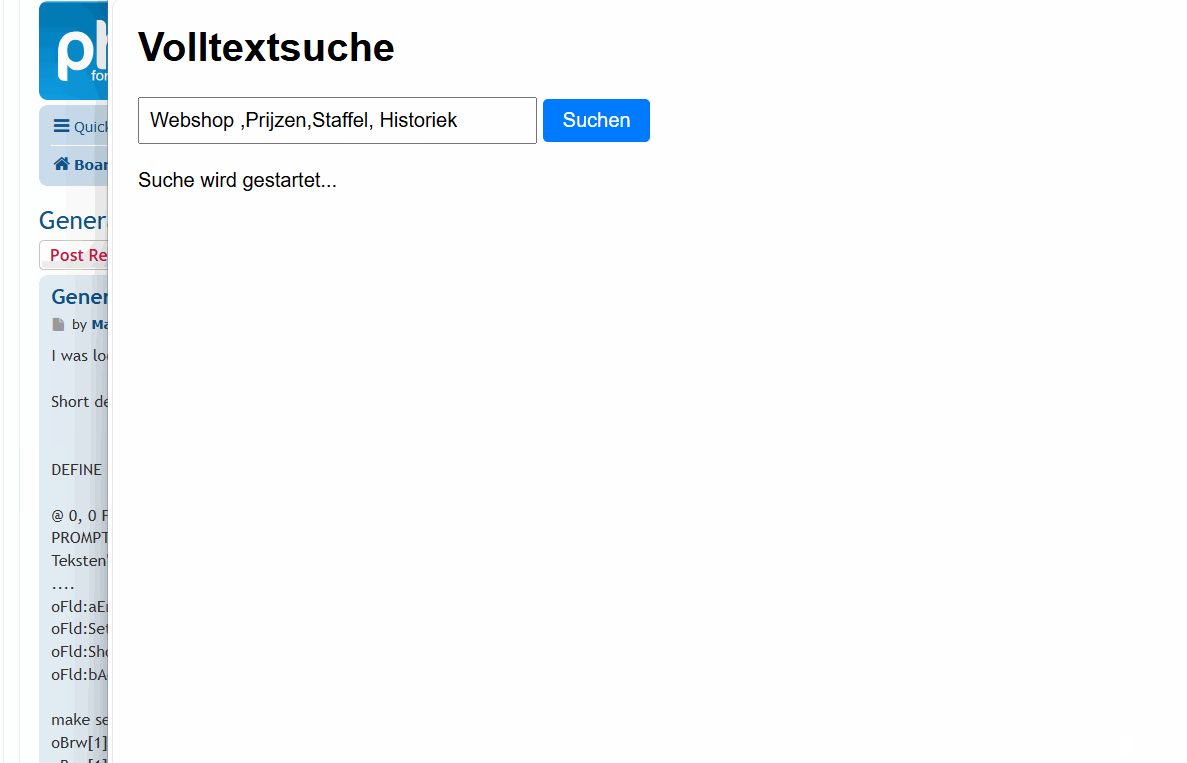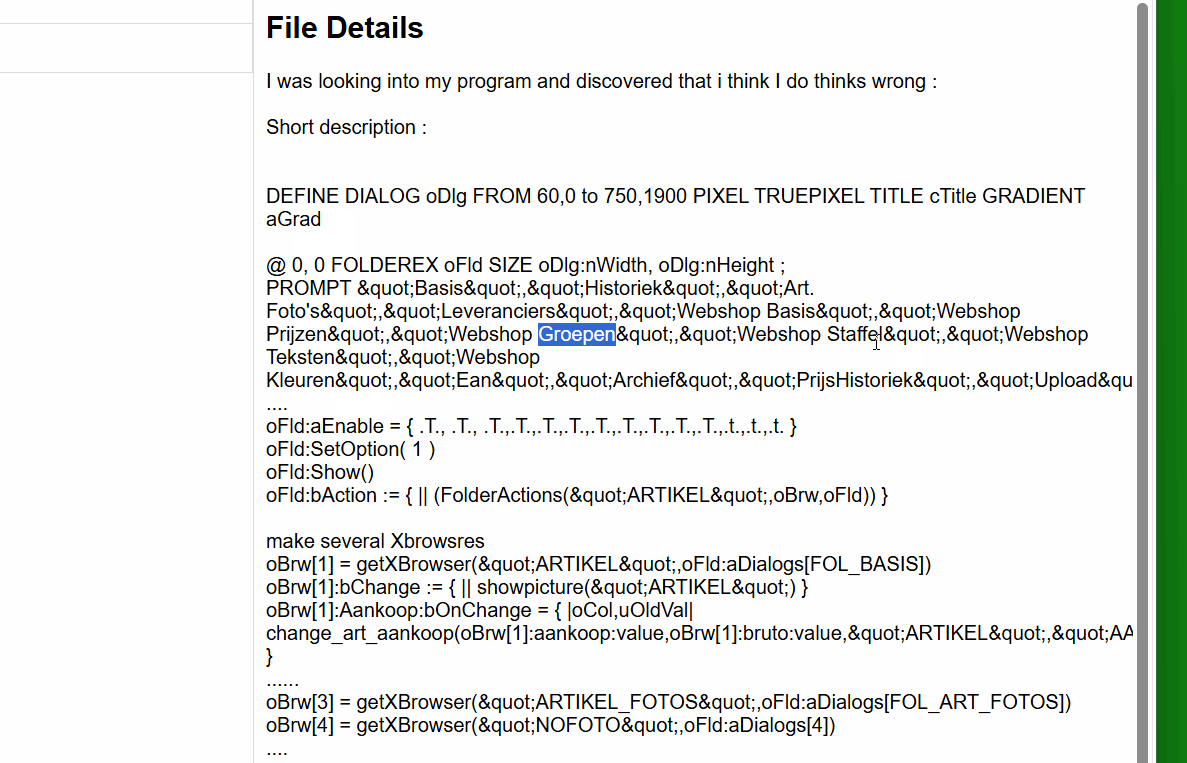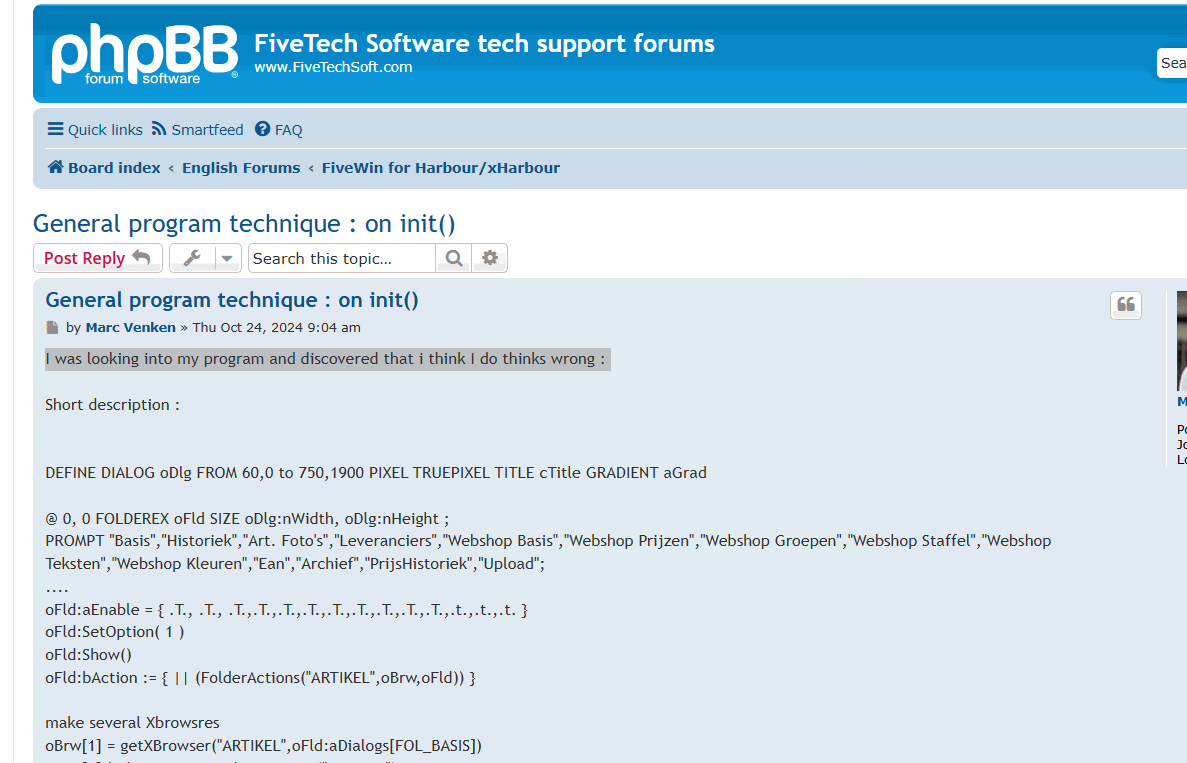
The outsourcing of memo fields into individual files can indeed be a practical and flexible alternative in modern systems and might better suit your DMS system.
That is exactly what I’m working on: a project where I create an index file from all the words in a directory. The index file follows the pattern: Word[TAB]Filename. My system is already working very well, but I wanted to share my approach and at the same time ask if anyone else is working on something similar. I’d love to exchange ideas and learn from your experiences!
My Solution Overview
One-time Creation of the Index File
I scan the directory and extract all words from the files.
For each word, I create an entry in the format Word[TAB]Filename and save everything in a main index file.
Ongoing Operation
During operation, the index file must be updated whenever files are deleted, edited, or added. My approach is as follows:
A. Deleting a File
I search the index file for all entries containing the filename.
These entries are removed from the index file.
B. Editing a File
First, I delete all entries in the index file that contain the filename.
Then I create a temporary index file with new entries from the edited file.
Finally, I append the temporary index file to the main index file.
C. Adding a New File
I create a temporary index file with entries from the new file.
This temporary index file is appended to the main index file.
Why This Approach?
Simplicity: The approach is easy to understand and implement.
Consistency: By deleting and recreating entries during edits, the index file always remains up to date.
Flexibility: Temporary index files allow changes to be processed in isolation before being merged into the main index file.
PS: Here’s a test
Just for info: the search is performed across 276,748 TXT files.
I split the forums DBF into individual memo files.
Search completed. Elapsed time: 0.9403415 seconds
Writing hash content to 'c:\search_results\results.txt'...
Results have been written to 'c:\search_results\results.txt'.
Writing matches with coverage to 'c:\search_results\matches_with_coverage.txt'...
Matches with coverage have been written to 'c:\search_results\matches_with_coverage.txt'.
********************************************************************
mod harbour - Vamos a la conquista de la Web
modharbour.org
https://www.facebook.com/groups/modharbour.club
********************************************************************
mod harbour - Vamos a la conquista de la Web
modharbour.org
https://www.facebook.com/groups/modharbour.club
********************************************************************
-
Antonio Linares
- Site Admin
- Posts: 42393
- Joined: Thu Oct 06, 2005 5:47 pm
- Location: Spain
- Has thanked: 9 times
- Been thanked: 41 times
- Contact:
Re: Antonio... FiveTouch posts are gone?
Dear Otto,
very interesting. Nice idea!
Could you please share the structure of the DBF and the used index key ?
Wondering if we should use user defined indexes entries, something possible using CDXs
very interesting. Nice idea!
Could you please share the structure of the DBF and the used index key ?
Wondering if we should use user defined indexes entries, something possible using CDXs
-
Antonio Linares
- Site Admin
- Posts: 42393
- Joined: Thu Oct 06, 2005 5:47 pm
- Location: Spain
- Has thanked: 9 times
- Been thanked: 41 times
- Contact:
Re: Antonio... FiveTouch posts are gone?
Dear Otto,
Looking into xHarbour docs I found this example. This came to my mind reading your post:
Looking into xHarbour docs I found this example. This came to my mind reading your post:
Code: Select all | Expand
// The example shows two approaches for building a custom index.
// In the first approach, the controlling index is a regular index
// which allows for relative database navigation. The second approach
// uses the custome index as controlling index and requires absolute
// database navigation. The first five logical records and physical records
// are added to the custome index.
REQUEST Dbfcdx
PROCEDURE Main
USE Customer VIA "DBFCDX"
INDEX ON Upper(LastName+FirstName) TAG NAME TO Cust01
INDEX ON Upper(LastName+FirstName) TAG NAMESET TO Cust01t CUSTOM
// relative navigation with non-custom index
OrdSetFocus( "NAME" )
GO TOP
FOR i:=1 TO 5
OrdKeyAdd( "NAMESET" )
SKIP
NEXT
GO TOP
Browse()
// absolute navigation with custom index
OrdSetFocus( "NAMESET" )
FOR i:=1 TO 5
DbGoto( i )
OrdKeyAdd( "NAMESET" )
NEXT
GO TOP
Browse()
USE
RETURN
OrdKeyAdd()
Adds an index key to a custom built index.
Syntax
OrdKeyAdd( [<nOrder>|<cIndexName>], ;
[<cIndexFile>] , ;
[<xIndexValue>] ) --> lSuccess
Arguments
<nOrder>
A numeric value specifying the ordinal position of the custom index open in a work area. Indexes are numbered in the sequence of opening, beginning with 1. The value zero identifies the controlling index.
<cIndexName>
Alternatively, a character string holding the symbolic name of the open custom index can be passed. It is analogous to the alias name of a work area. Support for <cIndexName> depends on the RDD used to open the index. Usually, RDDs that are able to maintain multiple indexes in one index file support symbolic index names, such as DBFCDX, for example.
<cIndexFile>
<cIndexFile> is a character string with the name of the file that stores the custom index. It is only required when multiple index files are open that contain indexes having the same <cIndexName>.
<xIndexValue>
This is the index value to be added to the index for the current record. It must be of the same data type as the value returned by the index expression. If omitted, <xIndexValue> is obtained by evaluating the index expression with the data of the current record. Return
The function returns .T. (true) if the current record is successfully included in the index, otherwise .F. (false) is returned.
Description
OrdKeyAdd() is used to build a custom index whose entries are programmatically added and deleted. Custom built indexes are not automatically updated by the RDD but are initially empty. OrdKeyAdd() adds the current record to the custom index and OrdKeyDel() removes it. It is possible to add multiple index values to the index for the same record, so that the same record is found when different search values are passed to DbSeek().
If no parameters are passed, OrdKeyAdd() evaluates the index expresssion with the data of the current record to obtain <xIndexValue>. The record is added to the index when it matches the FOR condition and scoping restrictions, if they are defined. When <xIndexValue> is specified, it must have the same data type as the value of the expression &(OrdKey()).
OrdKeyAdd() fails if the record pointer is positioned on Eof(), if the specified index is not a custom index, or if the specified index does not exist.
This is important when the custom index is the controlling index. Since a custome index is initially empty, relative database navigation with SKIP positions the record pointer always at Eof(). To include records to a controlling custom index, they must be physically navigated to using DbGoto().
The recommended way of creating a custom index is to use a non-custom index as the controlling index, skip through the database and specify <cIndexName> for OrdListAdd() when the current record meets the conditions for being included in the custom index.
-
Otto
- Posts: 6396
- Joined: Fri Oct 07, 2005 7:07 pm
- Has thanked: 8 times
- Been thanked: 1 time
- Contact:
Re: Antonio... FiveTouch posts are gone?
Dear Antonio,
I made this function to export the memofields:
And I use to create the indexfile this powershell:
This takes hours to build the index!
But CRUD functions for index lines works fast.
Best regards,
Otto
I made this function to export the memofields:
Code: Select all | Expand
#include "fivewin.ch"
REQUEST DBFCDX
REQUEST DBFFPT
static nCount := 0
function main
local cDBF_Dir := ".\dataTest\pages"
local cDBF_file_noPath := "c:\fwh\samples\DataTest"
local cDBF_file_memo := ""
local cDBF_fil_new := "PAGES_NEW"
local aStruc := {}
local cTmpDbf := ""
local cSrc := "c:\forumposts\forums.dbf" // "c:\fwh\samples\DataTest\PAGES.DBF"
local cDst := "c:\forumposts\forumsext.dbf" // "c:\fwh\samples\DataTest\PAGESext.dbf"
local cTempMatchcode := ""
local aFeld := {}
local aField := {}
local nField
local cFieldSubdir
local cDBF_memofiles := ""
use (cSrc) new
aStruc := DBStruct()
use
//cFilePath( cSrc ) // returns path of a filename
//cFileNoExt( cSrc ) // returns the filename without ext
cDBF_memofiles := cFilePath( cSrc ) + cFileNoExt( cSrc ) + "ext"
IF lisdir(cDBF_memofiles) = .f.
lmkdir(cDBF_memofiles)
ENDIF
// Adjust structure: Replace memo fields with character fields of length 50 and add prefix M_
FOR EACH aField IN aStruc
IF aField[2] == "M"
aField[1] := "M_" + aField[1] // Add prefix M_
aField[2] := "C"
aField[3] := 50
ENDIF
NEXT
if file(cDst) = .F.
DbCreate(cDst, aStruc)
endif
use
use(cDst) new ALIAS neuedbf
use(cSrc) new ALIAS altedbf
select altedbf
do while .not. eof()
aFeld := getrec()
// Export memo fields to txt files and save the file name in the character field
FOR nField := 1 TO fcount()
IF fieldType(nField) == "M"
cFieldSubdir := cDBF_memofiles + "\" + fieldName(nField) + "_memo"
// Create subdirectory for the memo field if not existing
IF lisdir(cFieldSubdir) = .f.
lmkdir(cFieldSubdir)
ENDIF
nCount += 1
cTempMatchcode := alltrim(str(recno())) + "-" + ShortUniqueIDNUM() + ALLTRIM( STR(nCount) )
MEMOWRIT(cFieldSubdir + "\" + cTempMatchcode + ".txt", fieldGet(nField), .F. )
aFeld[nField] := cTempMatchcode
ENDIF
NEXT
select neuedbf
APPEND_BLANK()
saverec(aFeld)
select altedbf
skip
enddo
? "Ende"
return
INIT PROCEDURE PrgInit
SET CENTURY ON
SET EPOCH TO YEAR(DATE())-98
SET DELETED ON
SET EXCLUSIVE OFF
REQUEST HB_Lang_DE
HB_LangSelect("DE")
SET DATE TO GERMAN
rddsetdefault("DBFCDX")
EXTERN DESCEND
RETURN
//----------------------------------------------------------------------------//
FUNCTION ShortUniqueIDNUM()
local cUniqueIDNUM := substr(dtos(date()),3) + "_" +;
substr(time(),1,2) + ;
substr(time(),4,2) + ;
substr(time(),7,2)
return (cUniqueIDNUM)
//----------------------------------------------------------------------------//
FUNCTION RLOK
if rlock()
RETURN ""
endif
DO WHILE .T.
if rlock()
exit
else
MsgInfo("Infobox","Datensatz gesperrt!")
endif
INKEY(.01)
ENDDO
RETURN ""
FUNCTION FLOK
if flock()
RETURN ""
endif
DO WHILE .T.
if flock()
exit
else
MsgInfo("Infobox","Datensatz gesperrt!")
endif
INKEY(.01)
ENDDO
RETURN ""
//----------------------------------------------------------------------------//
FUNCTION APPEND_BLANK
APPEND BLANK
DO WHILE NETERR()
APPEND BLANK
INKEY(.1)
ENDDO
unlock
rlok()
RETURN ""
//----------------------------------------------------------------------------//
FUNCTION unlok
unlock
RETURN (NIL)
//----------------------------------------------------------------------------//
FUNCTION net_use(vcFile,vlExclus,vnWait,vcAlias)
* tries to open a file for exclusive or shared use
*
* Syntax: NET_USE(expC1,expL1,expN1,expC2)
* where: expC1 = database to use, character string
* expL1 = .T. to use file exclusively, .F. for multi-user
* expN1 = seconds to wait if file isnt opened (0=forever), if >0,
* the calling routine must be constructed to handle cases
* where the file is not opened!
* expC2 = data driver
*
local forever := (vnWait=0)
*
do while (forever .or. vnWait>0)
if vlExclus && exclusive
use (vcFile) exclusive new
else
use (vcFile) shared new
endif
if .not. neterr() && USE succeeds
RETURN (.T.)
endif
*
inkey(1) && wait 1 second
vnWait--
ENDDO
RETURN (.F.) && database opening unsuccessful!
//----------------------------------------------------------------------------//
FUNCTION getRec()
local ary := {}
local nFcnt, nFnum
nFcnt = fcount()
FOR nFnum = 1 to nFcnt
aAdd(ary, fieldGet(nFnum))
NEXT
RETURN (ary)
//----------------------------------------------------------------------------//
FUNCTION saveRec(ary)
local nFcnt, nFnum
nFcnt = fcount()
FOR nFnum = 1 to nFcnt
fieldPut(nFnum, ary[nFnum])
NEXT
RETURN (NIL)
//----------------------------------------------------------------------------//
And I use to create the indexfile this powershell:
Code: Select all | Expand
# Pfade zu den zu durchsuchenden Verzeichnissen
$verzeichnisse = @(
"C:\www\htdocs\fwforum\data\forumsext\Dir1",
"C:\www\htdocs\fwforum\data\forumsext\Dir2",
"C:\www\htdocs\fwforum\data\forumsext\Dir3",
"C:\www\htdocs\fwforum\data\forumsext\Dir4",
"C:\www\htdocs\fwforum\data\forumsext\Dir5",
"C:\www\htdocs\fwforum\data\forumsext\Dir6",
"C:\www\htdocs\fwforum\data\forumsext\Dir7",
"C:\www\htdocs\fwforum\data\forumsext\Dir8"
)
# Pfad zur Indexdatei
$indexFile = "C:\suchergebnis\index.txt"
# Ergebnisverzeichnis sicherstellen
$ergebnisVerzeichnis = "C:\suchergebnis"
if (-not (Test-Path -Path $ergebnisVerzeichnis)) {
New-Item -ItemType Directory -Path $ergebnisVerzeichnis | Out-Null
}
# Indexdatei initialisieren (leeren oder erstellen)
if (Test-Path $indexFile) {
Clear-Content $indexFile
} else {
New-Item -Path $indexFile -ItemType File | Out-Null
}
# Funktion zur Indexerstellung
function Build-Index {
param (
[string[]]$Directories,
[string]$IndexPath
)
foreach ($dir in $Directories) {
Write-Host "Indexiere Verzeichnis: $dir" -ForegroundColor Green
# Alle .prg und .txt Dateien durchsuchen
$files = Get-ChildItem -Path $dir -Recurse -Include *.prg, *.txt -File
foreach ($file in $files) {
Write-Host " Verarbeite Datei: $($file.FullName)" -ForegroundColor Yellow
try {
# Dateiinhalt lesen
$content = Get-Content -Path $file.FullName -Raw
# Tokenisierung: Wörter extrahieren (nur alphanumerische Zeichen)
$words = $content -split '\W+' | Where-Object { $_ -match '\w+' } | ForEach-Object { $_.ToLower() }
# Einzigartige Wörter
$uniqueWords = $words | Sort-Object -Unique
foreach ($word in $uniqueWords) {
# Indexzeile: Wort<TAB>Dateipfad
"$word`t$($file.FullName)" | Out-File -FilePath $IndexPath -Append -Encoding ASCII
}
}
catch {
Write-Host " Fehler beim Verarbeiten von $($file.FullName): $_" -ForegroundColor Red
}
}
}
Write-Host "Indexierung abgeschlossen." -ForegroundColor Green
}
# Funktion zur Suche im Index
function Search-Index {
param (
[string]$SearchTerm,
[string]$IndexPath
)
$searchTerm = $SearchTerm.ToLower()
Write-Host "Suche nach: '$searchTerm'" -ForegroundColor Cyan
# Suche nach dem Wort am Anfang der Zeile (um genaue Übereinstimmung zu gewährleisten)
$pattern = "^$searchTerm`t"
$results = Select-String -Path $IndexPath -Pattern $pattern | ForEach-Object { $_.Line.Split("`t")[1] }
# Ausgabe der gefundenen Dateien
if ($results) {
Write-Host "Gefundene Dateien:" -ForegroundColor Green
$results | Sort-Object -Unique | ForEach-Object { Write-Host $_ }
}
else {
Write-Host "Keine Treffer gefunden." -ForegroundColor Yellow
}
return $results
}
# Zeitmessung starten
$startzeit = Get-Date
# Index erstellen
Build-Index -Directories $verzeichnisse -IndexPath $indexFile
# Zeitmessung beenden
$endzeit = Get-Date
$dauer = $endzeit - $startzeit
# Dauer anzeigen
Write-Host "Indexierungsdauer: $($dauer.TotalSeconds) Sekunden" -ForegroundColor Cyan
# Größe der Indexdatei messen
$indexSize = (Get-Item $indexFile).Length
Write-Host "Größe der Indexdatei: $indexSize Bytes" -ForegroundColor Cyan
# Beispielhafte Suchanfrage
$searchBegriff = "volltxtSearch"
$gefunden = Search-Index -SearchTerm $searchBegriff -IndexPath $indexFile
# Größe der Originaldateien messen
$originalSize = ($verzeichnisse | ForEach-Object {
Get-ChildItem -Path $_ -Recurse -Include *.prg, *.txt -File | Measure-Object -Property Length -Sum
}).Sum
Write-Host "Gesamtgröße der Originaldateien: $originalSize Bytes" -ForegroundColor Cyan
# Vergleich der Größen
$sizeRatio = [math]::Round(($indexSize / $originalSize) * 100, 2)
Write-Host "Indexgröße als Prozentsatz der Originaldateien: $sizeRatio%" -ForegroundColor Cyan
But CRUD functions for index lines works fast.
Best regards,
Otto
********************************************************************
mod harbour - Vamos a la conquista de la Web
modharbour.org
https://www.facebook.com/groups/modharbour.club
********************************************************************
mod harbour - Vamos a la conquista de la Web
modharbour.org
https://www.facebook.com/groups/modharbour.club
********************************************************************